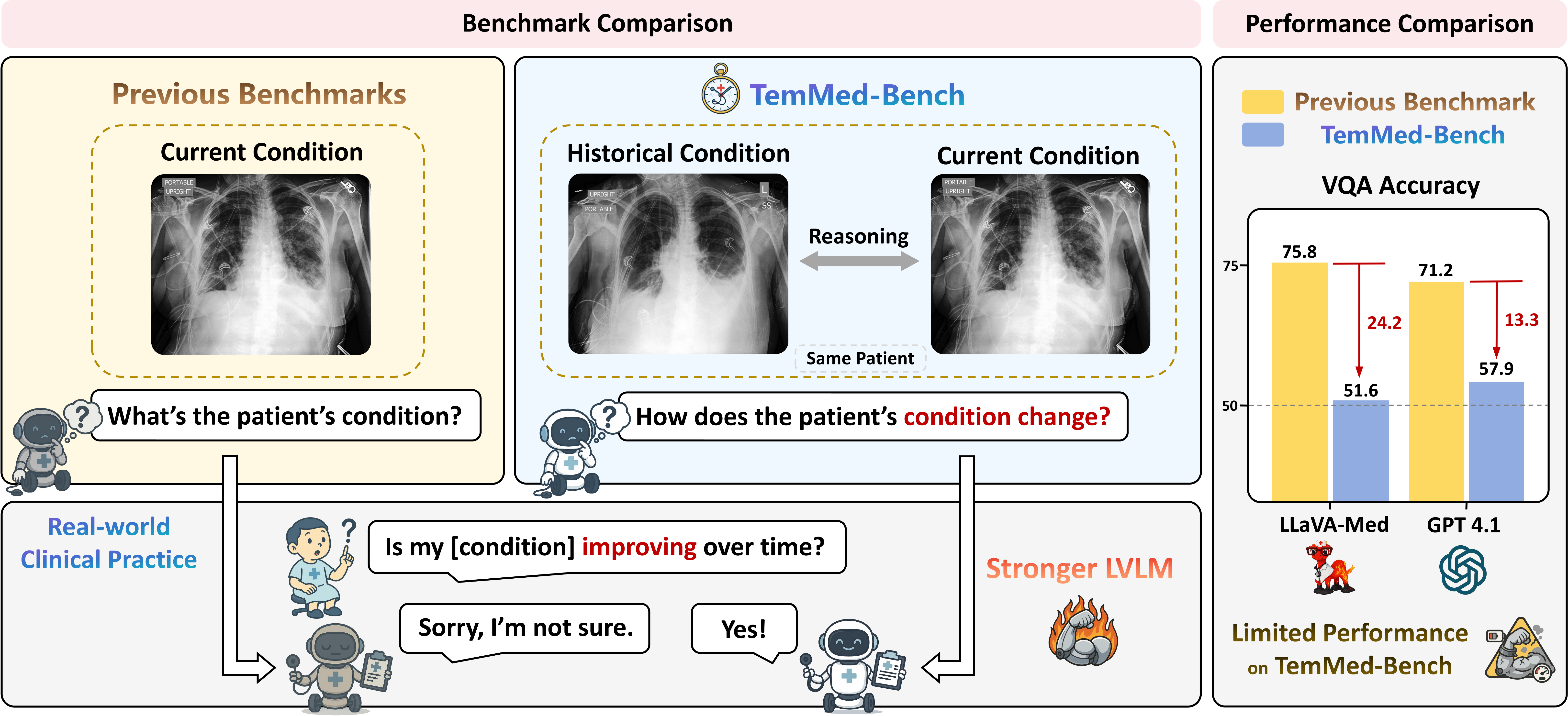
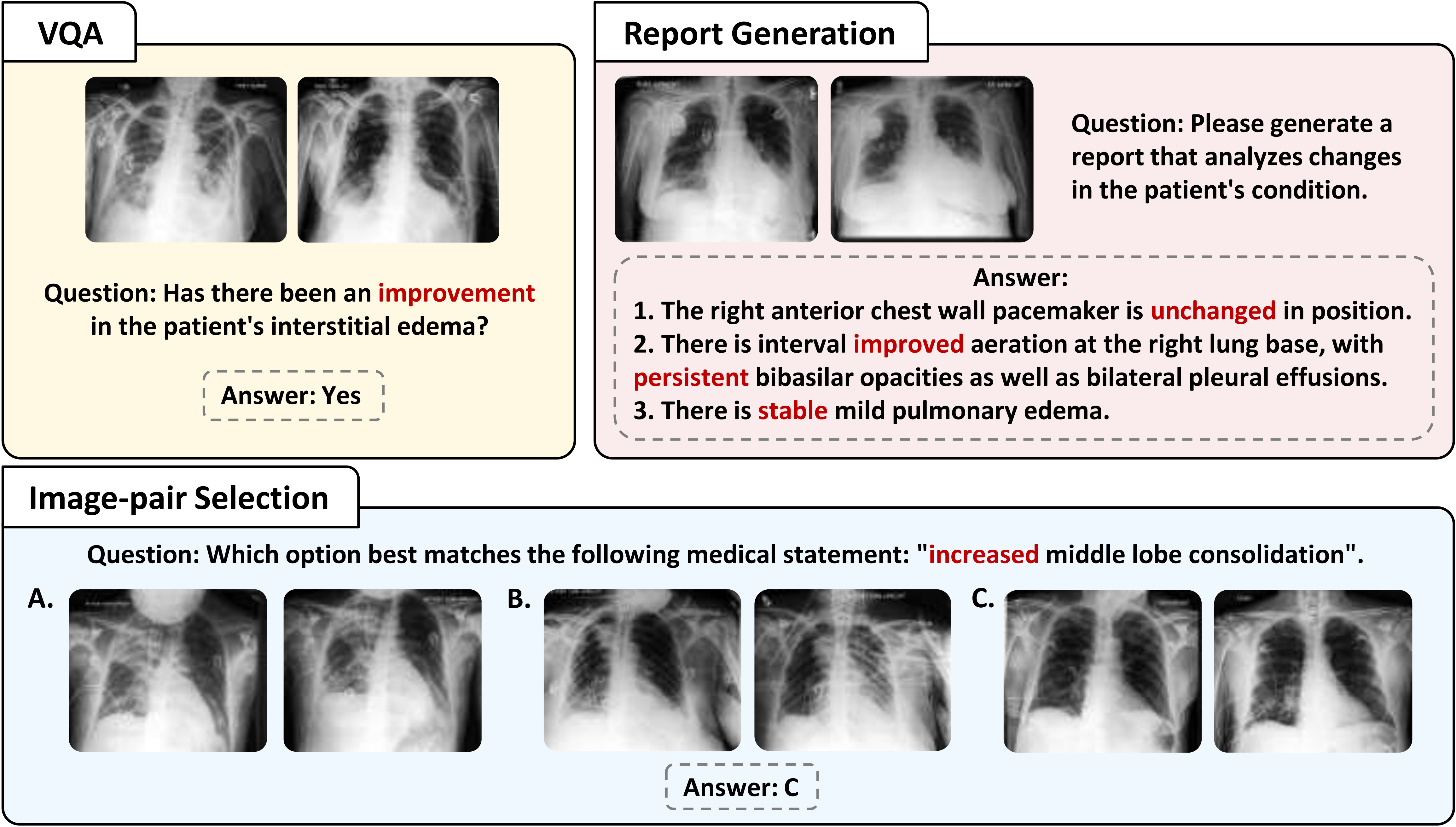
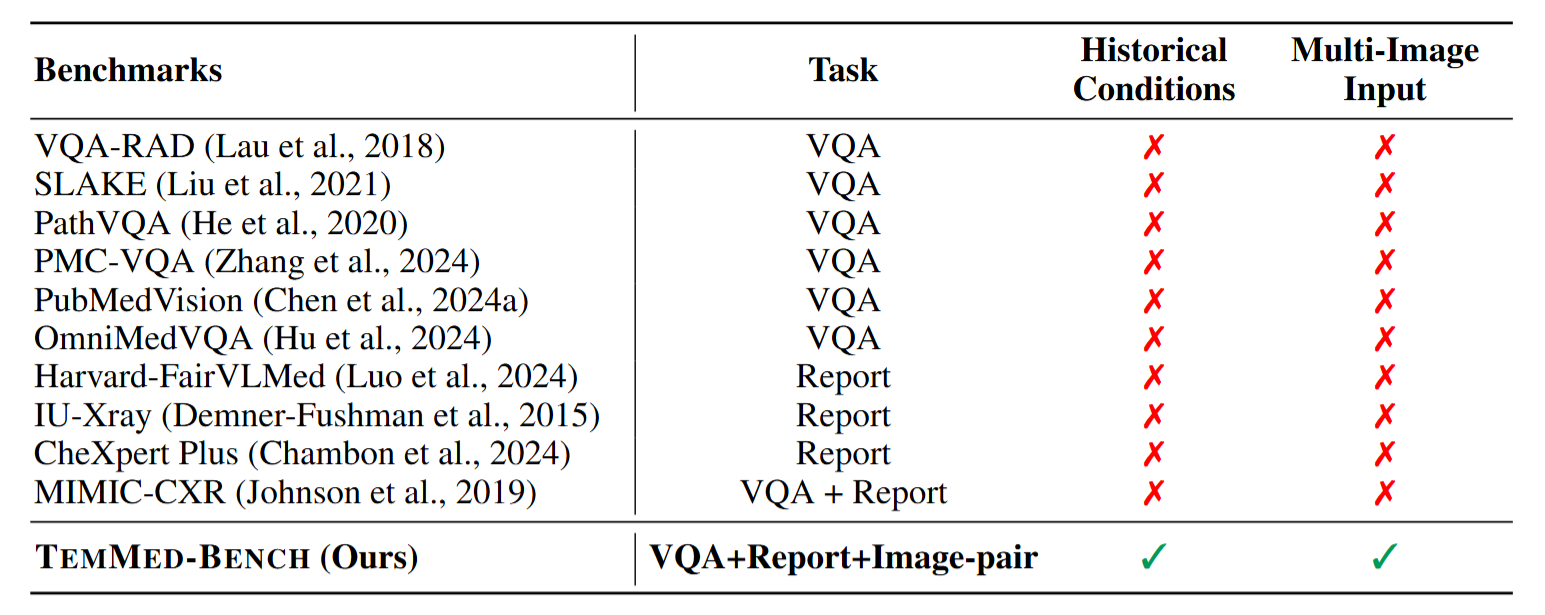
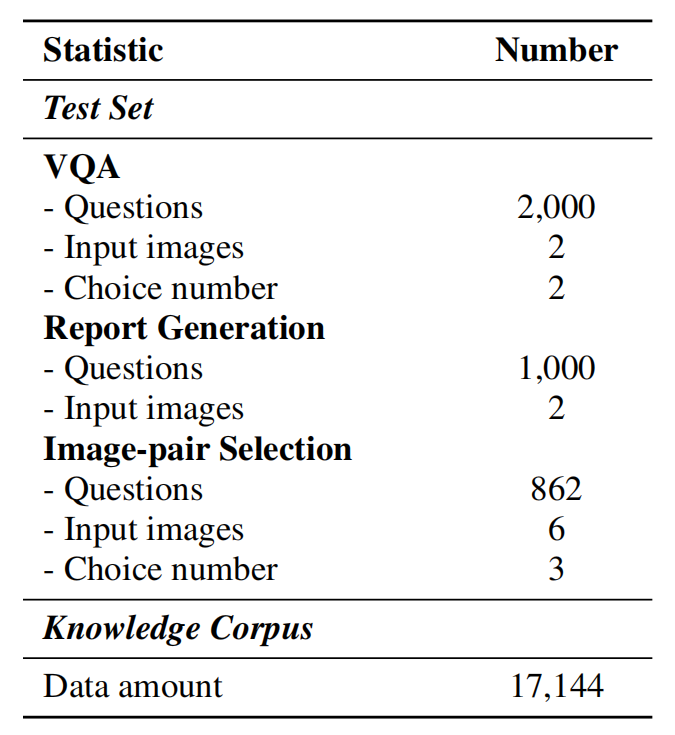
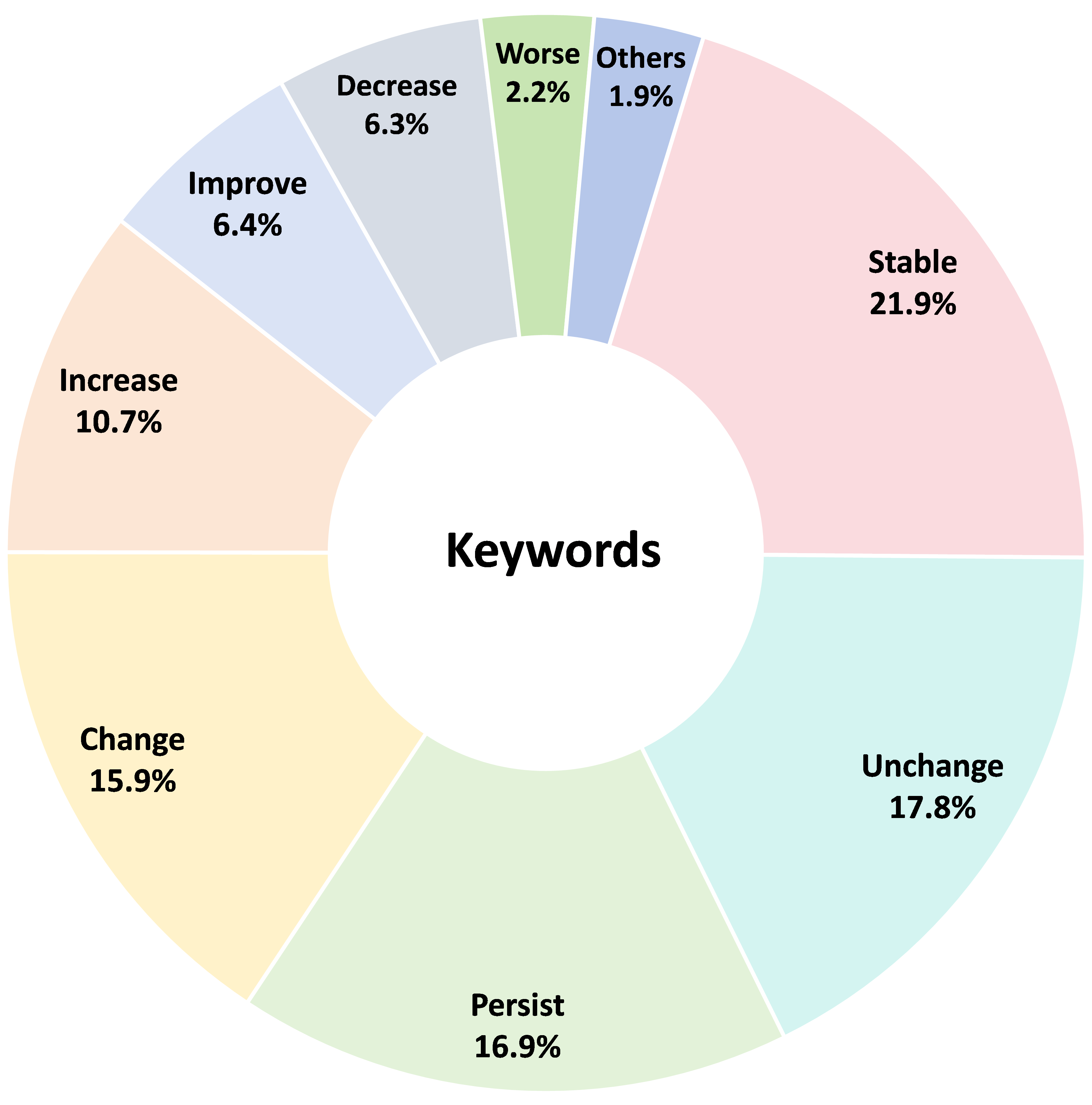
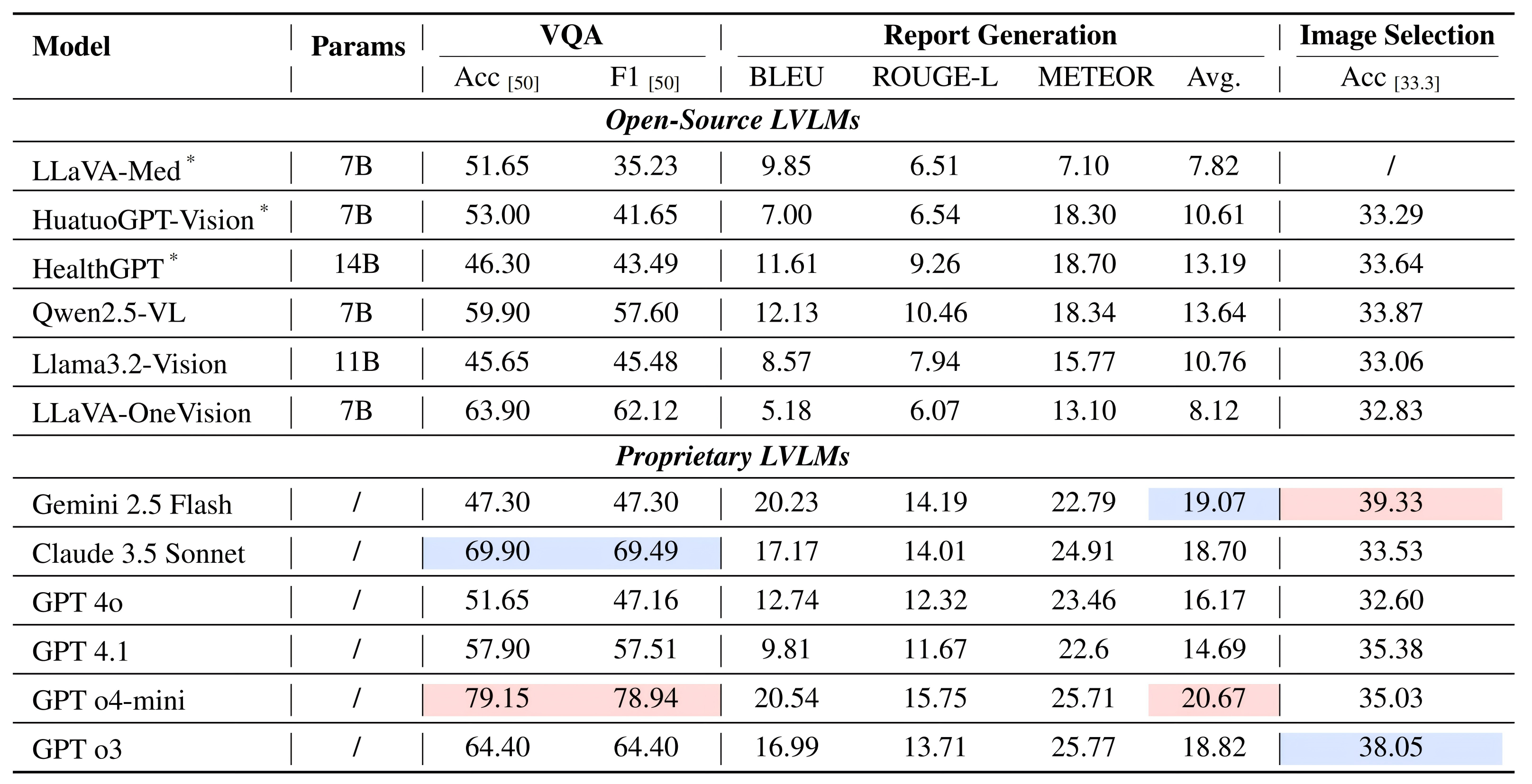
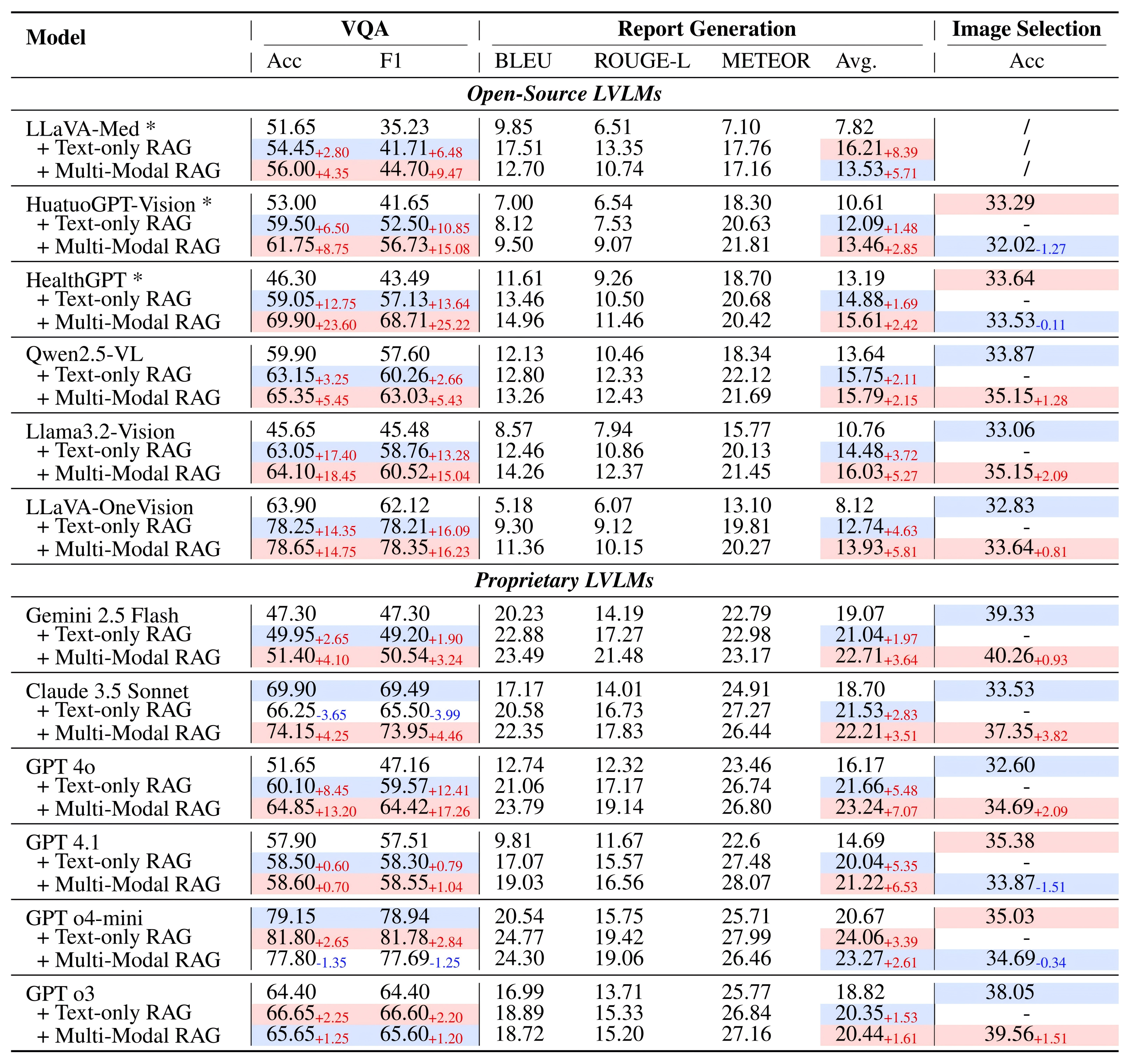
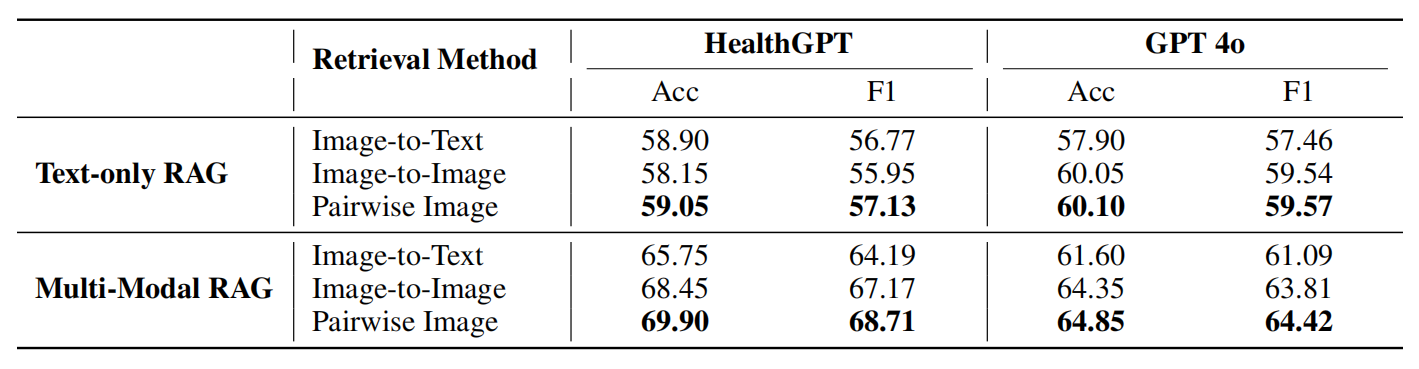
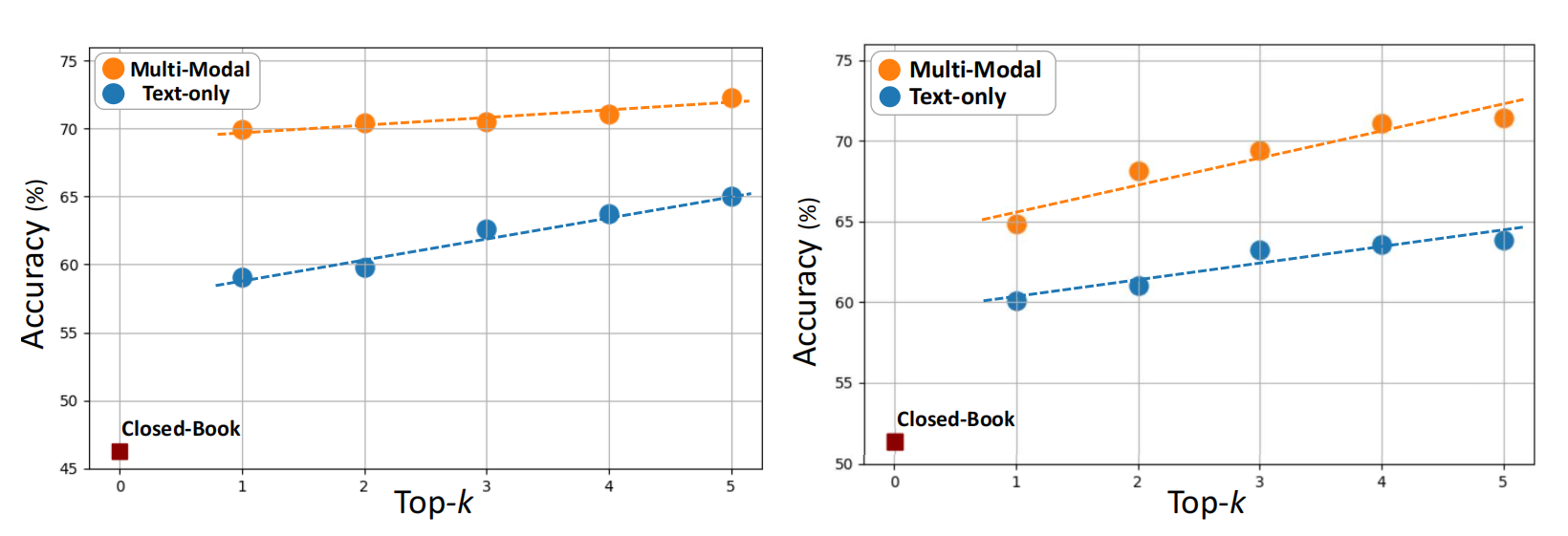
Existing medical reasoning benchmarks for vision-language models primarily focus on analyzing a patient's condition based on an image from a single visit. However, this setting deviates significantly from real-world clinical practice, where doctors typically refer to a patient's historical conditions to provide a comprehensive assessment by tracking their changes over time. In this paper, we introduce TemMed-Bench, the first benchmark designed for analyzing changes in patients' conditions between different clinical visits, which challenges large vision-language models (LVLMs) to reason over temporal medical images. TemMed-Bench consists of a test set comprising three tasks - visual question-answering (VQA), report generation, and image-pair selection - and a supplementary knowledge corpus of over 17,000 instances. With TemMed-Bench, we conduct an evaluation of twelve LVLMs, comprising six proprietary and six open-source models. Our results show that most LVLMs lack the ability to analyze patients' condition changes over temporal medical images, and a large proportion perform only at a random-guessing level in the closed-book setting. In contrast, GPT o3, o4-mini and Claude 3.5 Sonnet demonstrate comparatively decent performance, though they have yet to reach the desired level. To enhance the tracking of condition changes, we explore augmenting the input with both retrieved visual and textual modalities in the medical domain. We also show that multi-modal retrieval augmentation yields notably higher performance gains than no retrieval and textual retrieval alone across most models on our benchmark, with the VQA task showing an average improvement of 2.59%. Overall, we compose a benchmark grounded on real-world clinical practice, and it reveals LVLMs' limitations in temporal medical image reasoning, as well as highlighting the use of multi-modal retrieval augmentation as a potentially promising direction worth exploring to address this challenge.